RCNN는 2-stage object detection RCNN 계열 (RCNN, Fast RCNN, Faster RCNN)의 시초 모델입니다.
2-Stage
첫번째, Object의 위치를 찾아내는 것.(Region Proposal)
두번째, Object의 클래스를 분류하는 것(Region Classification)
수행 프로세스


1. Region Proposal 알고리즘을 사용하여 약 2000개의 Region 영역을 제안합니다.
2. CNN 네트워크에 입력하기 위해 동일한 사이즈의 입력 이미지가 필요하기에, Image crop(이미지 자르기)과 wrap(이미지 찌그러트림)를 사용하여 입력 이미지 사이즈를 맞춰줍니다.
3. CNN 네트워크로 feature를 추출하여 Region에 대하여 각각 어떤 클래스인지 SVM classifier로 클래스를 분류합니다.
4. 마지막으로, 추출된 feature로부터 바운딩박스의 위치를 조정해나아가기위해 regression을 수행합니다.
1. Object 후보영역 찾기
object detection에서 위치를 찾아내는 방식은 크게 두가지 Sliding window 방식과 Region Proposal 방식으로 이루어집니다.
Sliding Window 방식
Sliding Windows는 다음과 같은 그림처럼 Window를 왼쪽 상단부터 오른쪽 하단으로 이동시키면서 object를 Detection하는 방식.

슬라이딩 윈도우 방식은 크게 두가지 방법으로 나뉘어집니다. 1. 다양한 window를 각각 sliding시키는 방식. 2. window scale를 고정시키고 scale를 변경한 여러 이미지를 사용하는 방식.
하지만, Slinding Window방식은 오브젝트가 없는 영역도 무조건 슬라이딩하며, 여러 형태의 window와 여러 scale을 가진 이미지를 스캔해서 object를 검출해야하므로 수행시간이 오래 걸리고 검출 성능이 떨어진다는 문제점이 있습니다.
Region Proposal
이를 해결하기 위해 나온 방식이 Region Proposal (영역추정방식)입니다. 간단히 말하자면, "object 가 있을 만한 후보 영역을 찾자"라고 말할 수 있겠습니다. 그 중 대표적인 알고리즘이 "Selective search"입니다.
이미지의 컬러, 무늬(texture), 크기(size), 형태(shape)과 같은 이미지 특징에 따라 유사한 Region을 계층적 그룹핑 방법으로 계산합니다. 구체적인 수행 프로세스는 다음과 같습니다.
2. Bounding Box Regression
예측한 박스좌표 ( 중심 x, y 좌표, 바운딩박스 너비, 높이)

정답 박스 좌표

바운딩 박스 수정함수

Regression Loss

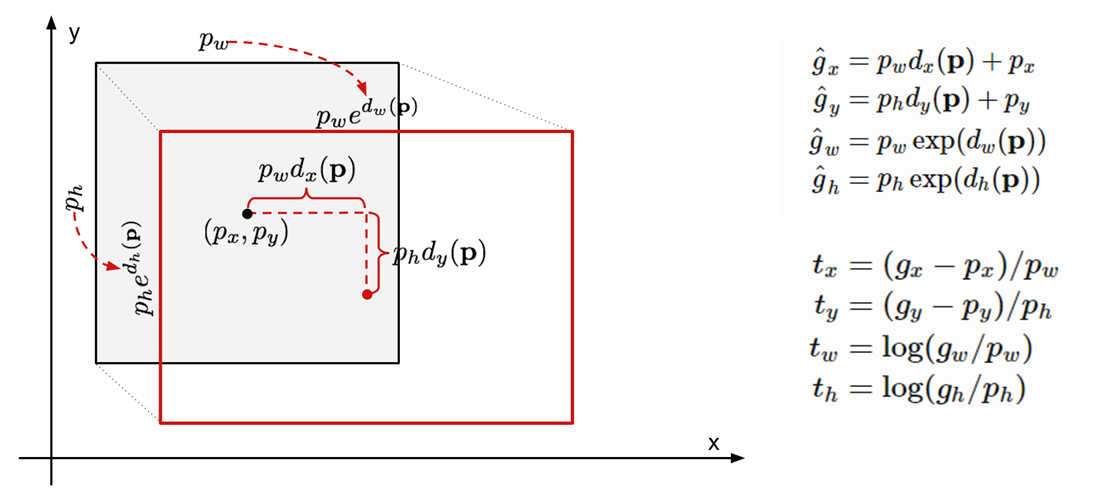
모델은 타겟(정답좌표와 예측좌표로부터 차이값)과 바운딩 박스 수정함수의 차이가 최소가 되도록 학습합니다.
3. 한계점
3-1.
Region proposal로 추출된 약 2000개의 영역에 대해서 각각 CNN을 통과시켜야 하므로 매우 긴 연산시간을 필요로 합니다.
3-2.
CNN, Bouding Box Regression, SVM 세가지 모델을 end-to-end로 학습시키지 않고 따로 따로 학습을 진행하고 있습니다.
구체적으로는 각각의 Region proposal 영역에 대해 CNN으로 특징을 추출하여 벡터로 Bounding Box와 SVM을 학습을 진행하고 있기에 Bounding Box와 SVM 학습 결과가 CNN의 학습에 반영되지 못하는 문제점이 있습니다.
4. 해결
위의 한계점을 해결하기 위해 모델이 Fast R-CNN이 제안되게 되었습니다.
'Computer Vision > Object Detection' 카테고리의 다른 글
| YOLO(You Only Look Once) (0) | 2022.08.24 |
|---|---|
| Fast/Faster RCNN 한눈에 비교 (0) | 2022.08.23 |
| FCOS(Fully Convolutional One-Stage Detector) (0) | 2022.08.21 |


